

科研进展
重庆研究院在自然语言问答的视频理解研究中取得进展
时间:2024-04-23编辑:智能安全技术研究中心
现有自然语言问答的视频理解研究大多采用离线特征提取方式来进行问答推理,然而这种离线的处理方式存在一些缺陷:(1)视频或文本特征提取器通常是在其他任务上进行训练的,与目标任务存在差异,如将行为识别数据集上训练的特征提取器直接用于视频问答任务显然不是最优的。(2)各个特征提取器通常是在各自领域数据集上单独进行训练,得到的模态特征之间缺乏联系。(3)为提升问答推理表现,这类方法通常需借助于复杂的特征提取器或文本分析工具以更有效地处理视频或问题。因此,采取端到端的方式来对自然语言问题和视频内容进行学习是解决上述缺陷的一种有效途径。尽管近年来提出的端到端方法通过同时学习特征提取与多模态信息交互,并在问答推理上取得了优异的识别表现。然而,这些方法主要关注于构建参数量庞大的模型以及探索如何利用大规模视觉文本语料库的预训练来提升任务性能,而这通常需要耗费大量的计算资源,且在数据标注和模型训练上具有较高的人力成本。
我院研究团队针对现有研究方法存在的上述问题,提出了一种高效的端到端视频和语言联合学习方法。该方法结合了现有研究中所验证的局部空间信息和时间动态特性对于提升问答推理准确性的帮助,通过设计金字塔式视频和语言交互结构,将视频分解成具有不同粒度的空间和时间特征,并堆叠多个多模态 Transformer层提取其与问题之间的交互,实现了视频和文本之间的局部和全局依赖关系提取。此外,为更充分地利用各层上的局部和全局交互特征,该方法设计了一种基于上下文匹配的横向连接操作以及多步损失约束,以逐步地实现局部和全局语义完整的交互特征的提取。
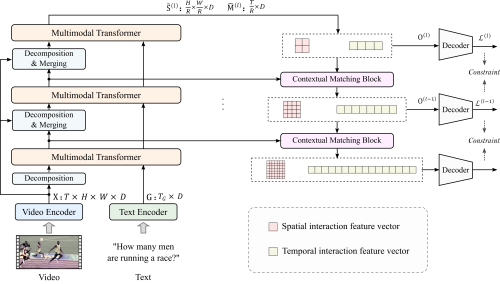
方法框架图
本研究方法能够在无需建立参数量庞大的特征提取以及交互模型,且在不借助于大规模视觉文本数据对预训练的情况下,取得与现有方法相比更好或相当的推理表现。同时在模型参数量和计算效率上具有显著优势。相关成果发表在人工智能顶会议AAAI Conference on Artificial Intelligence(CCF A类)上。上述工作得到国家自然科学基金项目的支持。相关论文链接:https://ojs.aaai.org/index.php/AAAI/article/view/25296
中国科学院重庆绿色智能技术研究院 版权所有京ICP备05002857号渝公网安备50010943035号

















